Who Am I?
Xiaoyong Wei is a visiting professor of the Department of Computing, The Hong Kong Polytechnic University. He has been a professor and the head of the Department of Computer Science, Sichuan University, China since 2010. He received his Ph.D. in Computer Science from the City University of Hong Kong and has worked as a postdoctoral fellow in the University of California, Berkeley. His research interests include Multimedia Computing, Health Computing, Machine Learning, and Large-Scale Data Mining. He is a senior member of IEEE, and has served as an associate editor of Interdisciplinary Sciences: Computational Life Sciences since 2020, the program chair of ICMR 2019, ICIMCS 2012, and the technical committee member of over 20 conferences such as ICCV, CVPR, ACM MM, ICME, SIGKDD, and ICIP.
Xiaoyong has been dedicating to his firm belief of teaching--research harmony. Most of his research ideas were inspired by teaching in which his focus is to build advanced AI technology to address classroom challenges. His work “Mining In-Class Social Networks for Large-Scale Pedagogical Analysis” has been considered as the first one to tackle in-school social networks (distinct from existing work using social media for after-school networks). His work of using drone patrol to analyze the students’ boredom level and teacher-student interactions has attracted extensive attention worldwide and been reported by mass media including BBC, The Telegraph, and CCTV. He has received the Pineapple Science Prize awarded by Dan Shechtman (Israel materials scientist and the Nobel Prize laureate), because these work while remaining as novel research, have also aroused the public enthusiasm for science.
Xiaoyong has recently initiated the Healthism project with Prof. Ramesh Jain of the University of California, Irvine. Healthism is an interdisciplinary project to tackle chronic diseases and significantly improve quality of life by going beyond the episodic health model developed for prevalent disease-centric-healthcare. Healthism focuses on physical and mental health to develop approaches for changing the way people adopt lifestyle for achieving best health to meet their desired goals.
Join Us
Positions avaliable include
- Research Assistants
- Ph.D.
- Postdoctoral Fellows
Desired Candidate Attributes
- Experience in machline learning (e.g., Computer Vision, Bioinformatics, NLP)
- Proficieny in programming languages (Python is perferred)
- Major in computer science or related (e.g., EE, Mathematics)
- A teamplayer
Selected Publications
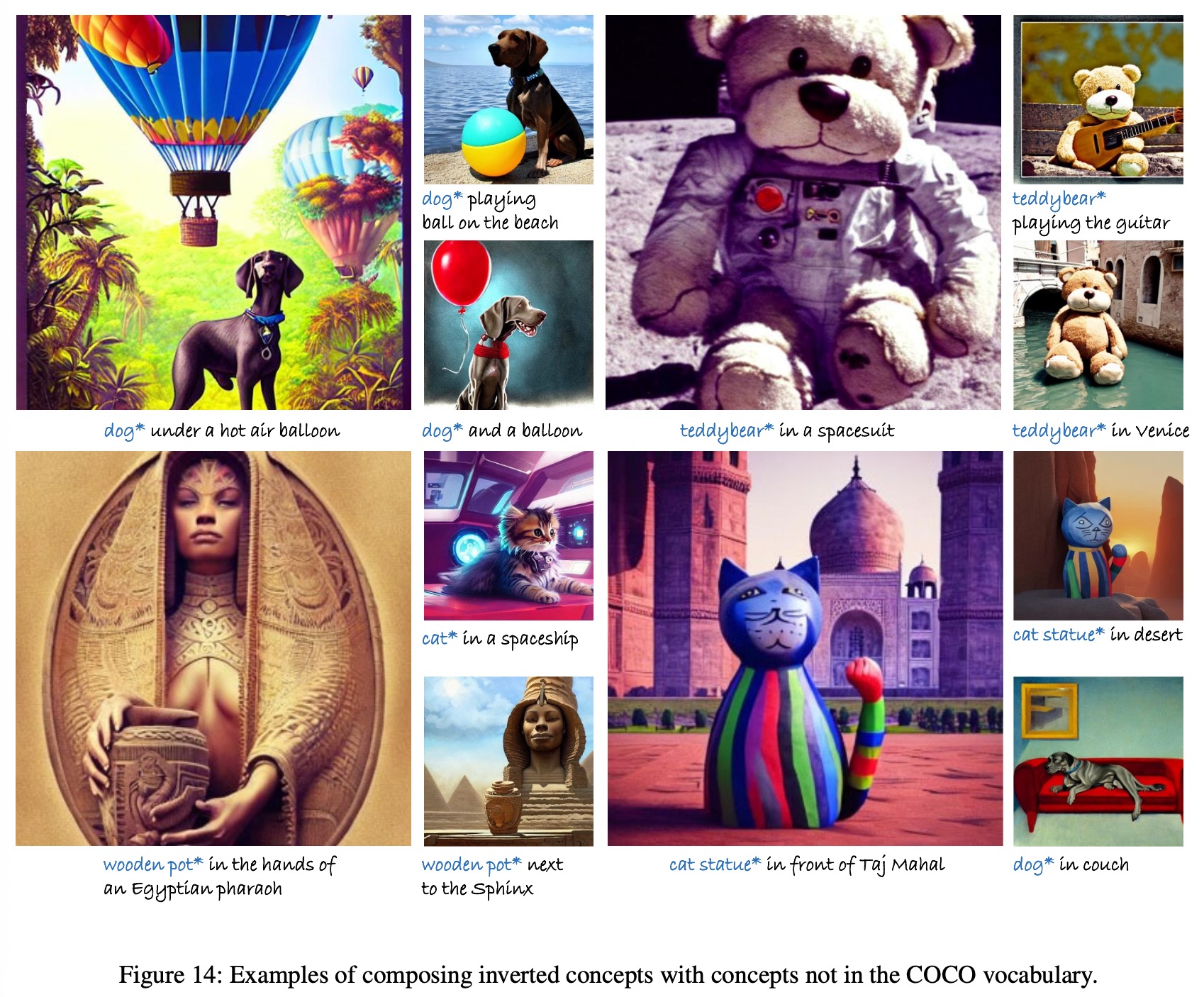
Compositional Inversion for Stable Diffusion Models, The 38th Annual AAAI Conference on Artificial Intelligence (AAAI), 2024
[PDF]
[CODE]
[BIBTEX]
[IMG]

@inproceedings{WXY_AAAI_2024,
author={Xu-Lu Zhang, Xiao-Yong Wei, Jin-Lin Wu, Tian-Yi Zhang, Zhao-Xiang Zhang, Zhen Lei, Qing Li},
booktitle={The 38th Annual AAAI Conference on Artificial Intelligence},
title={Compositional Inversion for Stable Diffusion Models},
year={2024}}
- We have identified a challenge in image generation using diffusion models, where the inverted concepts obtained through inversion methods lack compositional coherence
- Our research reveals that the compositional nature of a concept relies on its position within the embedding space. There exists a core distribution where concepts are well-trained and easily combinable, while concepts further away from this core distribution pose greater challenges for composition
- To tackle this issue, we propose a solution that guides the inversion process towards the core distribution, promoting compositional embeddings. Additionally, we introduce a spatial regularization approach to balance attention among the concepts being composed
- Our method is designed as a post-training approach and can be seamlessly integrated with other inversion methods
Rethinking Multimodal Entity and Relation Extraction from a Translation Point of View, The 61st Annual Meeting of the Association for Computational Linguistics (ACL), 2023
[PDF]
[CODE]
[BIBTEX]
[IMG]
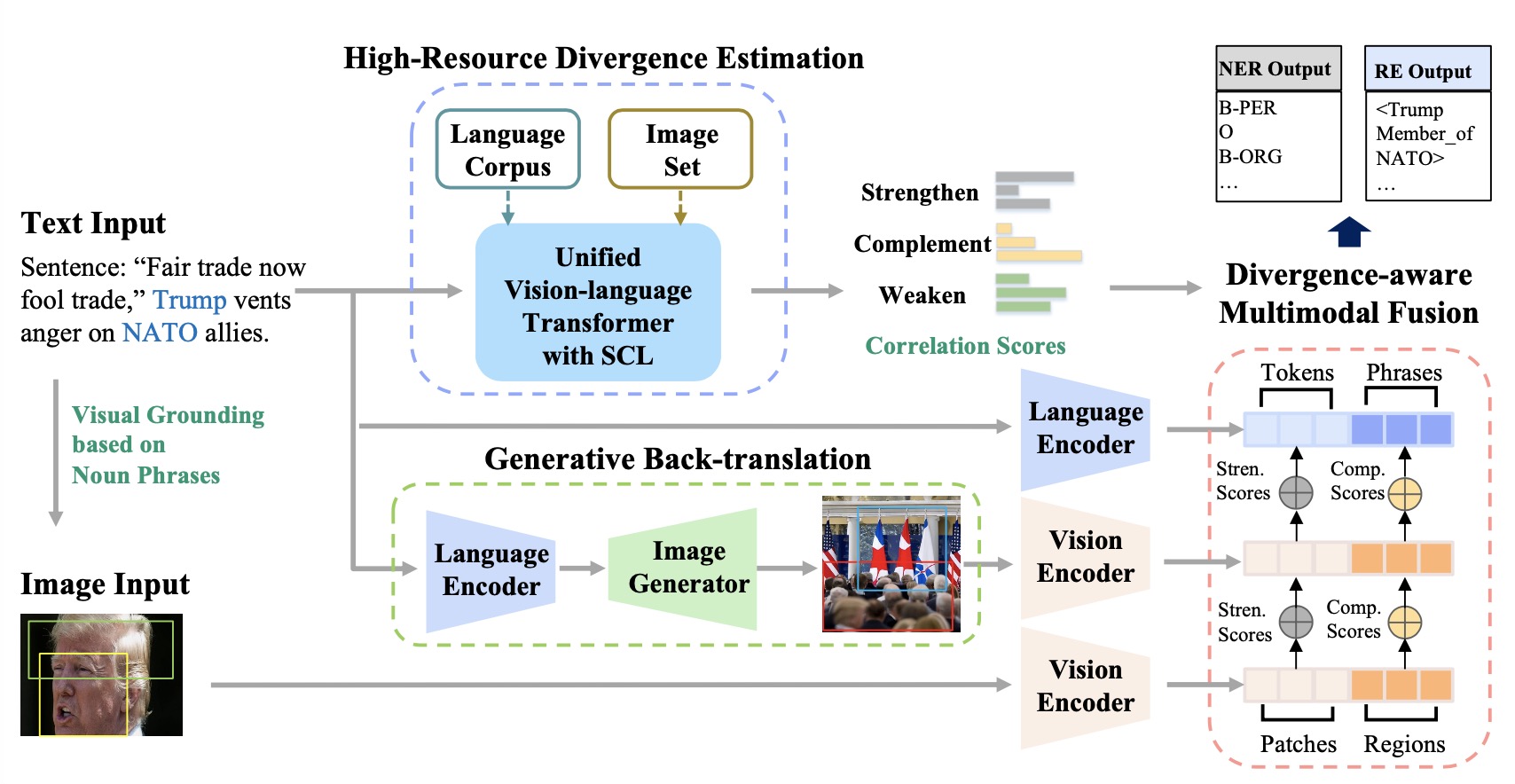
@inproceedings{WXY_ACL_2023,
author={Changmeng Zheng, Junhao Feng, Yi Cai, Xiaoyong Wei, Qing Li},
booktitle={The 61st Annual Meeting of the Association for Computational Linguistics},
title={Rethinking Multimodal Entity and Relation Extraction from a Translation Point of View},
year={2023}}
- We revisit the multimodal entity and relation extraction from a translation point of view by identifying that the cross-modal misalignment is a similar problem of cross-lingual divergence issue in machine translation
- We address the misalignment issue in text-image datasets by treating a text and its paired image as the translation to each other, so that the the misalignment can be estimated by compare the text with its “back-translation”
- We implement a multimodal back-translation using diffusion based generative models for pseudo-paralleled pairs and a divergence estimator by constructing a high-resource corpora as a bridge for low-resource learners
Identifying The Kind Behind SMILES - Anatomical
Therapeutic Chemical Classification using Structure-Only Representations, Briefings in Bioinformatics, 2022
[PDF]
[CODE]
[BIBTEX]
[IMG]

@ARTICLE{WXY_ATC_2022,
author={Yi Cao, Zhen-Qun Yang, Xu-Lu Zhang, Wenqi Fan, Yaowei Wang, Jiajun Shen, Dong-Qing Wei, Qing Li, Xiao-Yong Wei},
journal={Briefings in Bioinformatics},
title={Identifying The Kind Behind SMILES - Anatomical
Therapeutic Chemical Classification using Structure-Only Representations},
year={2022},
volume={23},
number={5},
pages={bbac346},
doi={https://doi.org/10.1093/bib/bbac346}}
- We demostrate the possiblity of eliminating the reliance on the costly lab experiments for drug design so that the characteristics of a drug can be preassessed for better decision-making and effort-saving before the actual development
- We propose a molecular-structure-only deep learning method which is built on statistically and physicochemically meaningful tokens so as to ensure better explainability
- We construct a new benchmark ATC-SMILES for ATC classification which is with a larger scale than traditional benchmarks
Deep Collocative Learning for Immunofixation Electrophoresis Image Analysis, IEEE Transactions on Medical Imaging, 40 (7), 1898-1910, 2021
[PDF]
[CODE]
[BIBTEX]
[IMG]
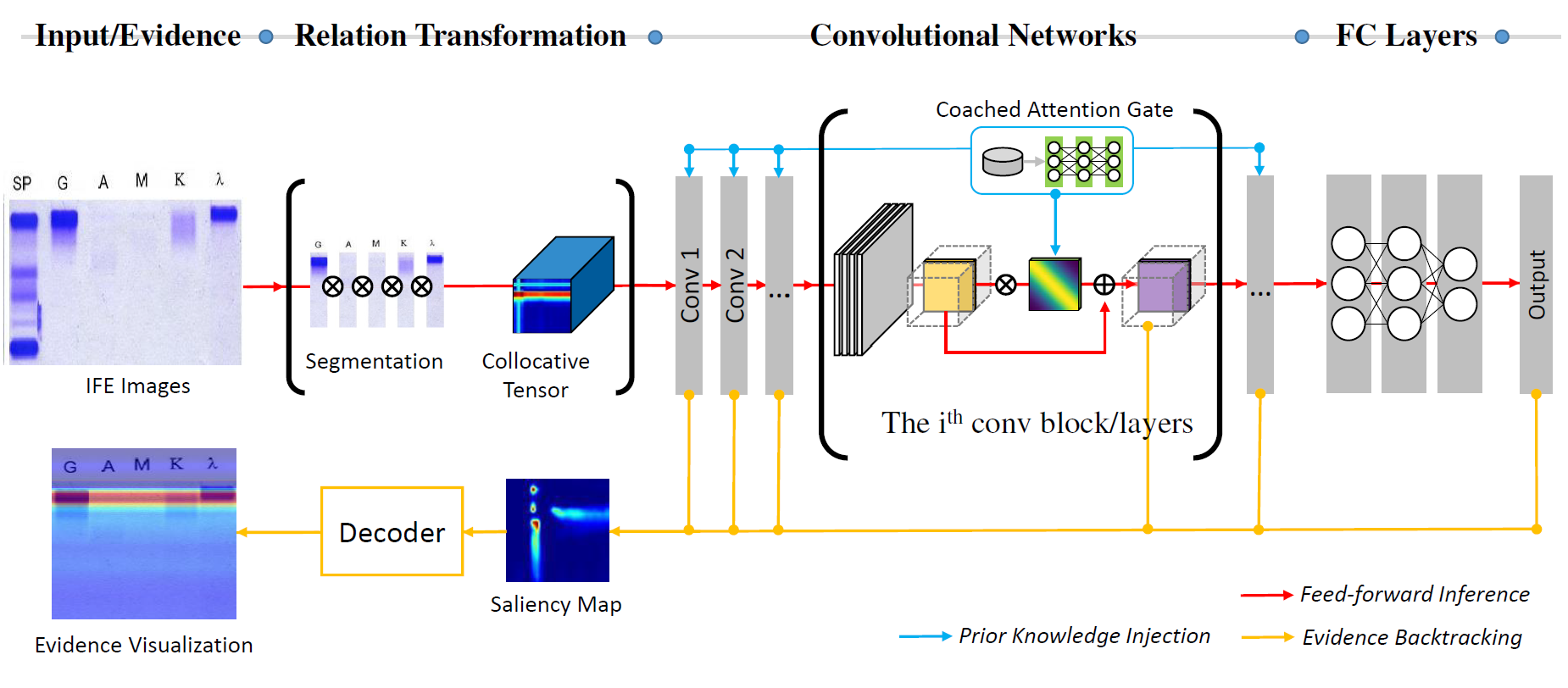
@ARTICLE{WXY_DCL_TMI_2021,
author={Wei, Xiao-Yong and Yang, Zhen-Qun and Zhang, Xu-Lu and Liao, Ga and Sheng, Ai-Lin and Zhou, S. Kevin and Wu, Yongkang and Du, Liang},
journal={IEEE Transactions on Medical Imaging},
title={Deep Collocative Learning for Immunofixation Electrophoresis Image Analysis},
year={2021},
volume={40},
number={7},
pages={1898-1910},
doi={10.1109/TMI.2021.3068404}}
- A learning paradigm which leverages the power of CNNs for binary (comparative) relation modeling
- A location-label-free method for localization
- A formulated way for human knowledge injection
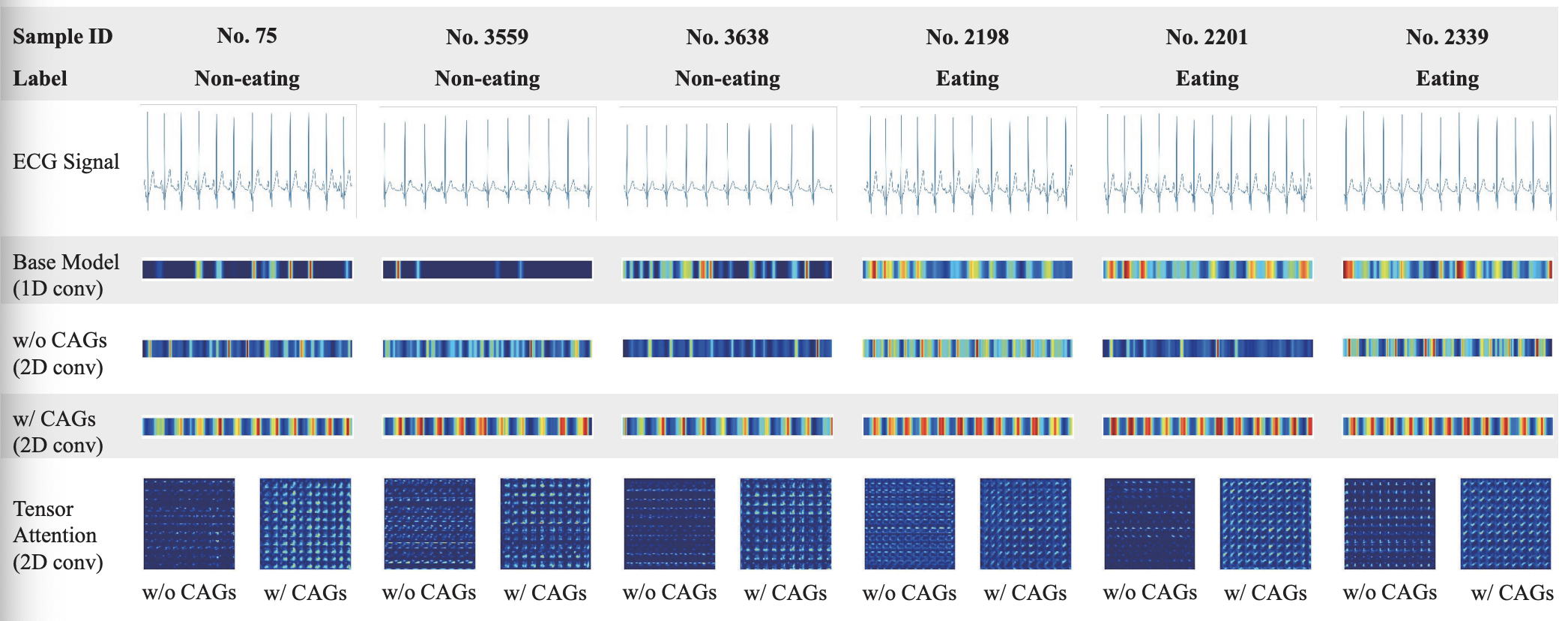
Cardiac Evidence Mining for Eating Monitoring using Collocative Electrocardiogram Imagining, TechRxiv, 2022
[PDF]
[CODE]
[BIBTEX]
[IMG]
@ARTICLE{WXY_ECG_2022,
author={Zhang, Xulu and Yang, Zhenqun and Jiang, Dongmei and Liao, Ga and Li, Qing and Jain, Ramesh and Xiao-Yong Wei},
journal={TechRxiv},
title={Cardiac Evidence Mining for Eating Monitoring using Collocative Electrocardiogram Imagining},
year={2022},
doi={https://doi.org/10.36227/techrxiv.18093275.v2}}
- We process the ECG singals in an image-liked way so as to bridge the gap between CNNs and signal processing
- We prove collocative learning is capable of modeling the periodic nature of the singals
- We make it possible to backtrack the cardiac evidence for eating behavior monitoring
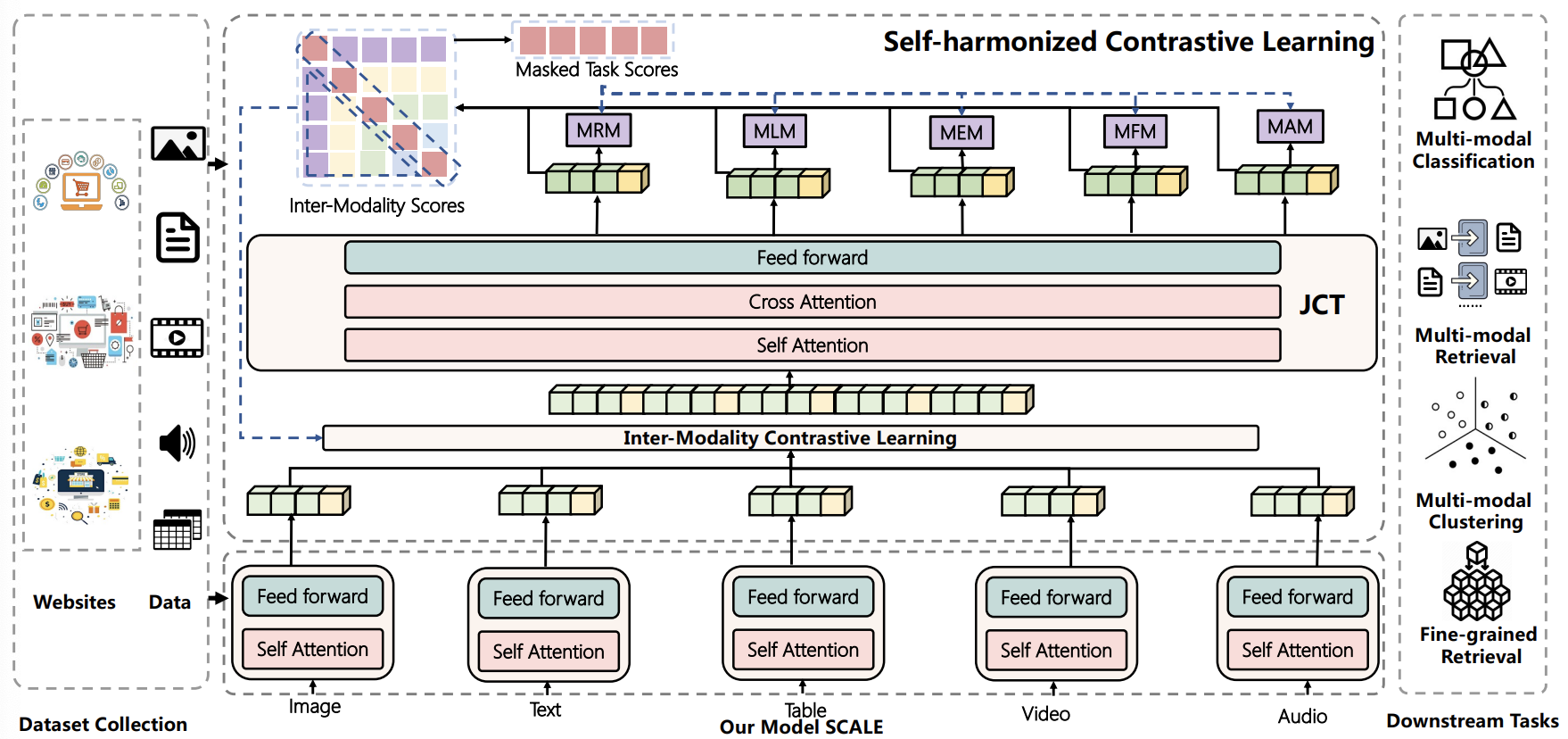
M5Product: Self-harmonized Contrastive Learning for E-commercial Multi-modal Pretraining, IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), 2022
[PDF]
[CODE]
[BIBTEX]
[IMG]
@inproceedings{WXY_CVPR_2022,
author={Xiao Dong and Xunlin Zhan and Yangxin Wu and Yunchao Wei and Michael C. Kampffmeyer and Xiao-Yong Wei and Minlong Lu and Yaowei Wang and Xiaodan Liang},
booktitle={IEEE/CVF International Conference on Computer Vision and Pattern Recognition},
title={M5Product: Self-harmonized Contrastive Learning for E-commercial Multi-modal Pretraining},
year={2022}}
- We contribute a large-scale multimodal E-commerce dataset
- The dataset is with 5 modalities (image, text, table, video, and audio), and includes over 6,000 categories and 5,000 attributes
- We propose Self-harmonized ContrAstive LEarning (SCALE), which demonstrates the SOTA performance in several downstream tasks
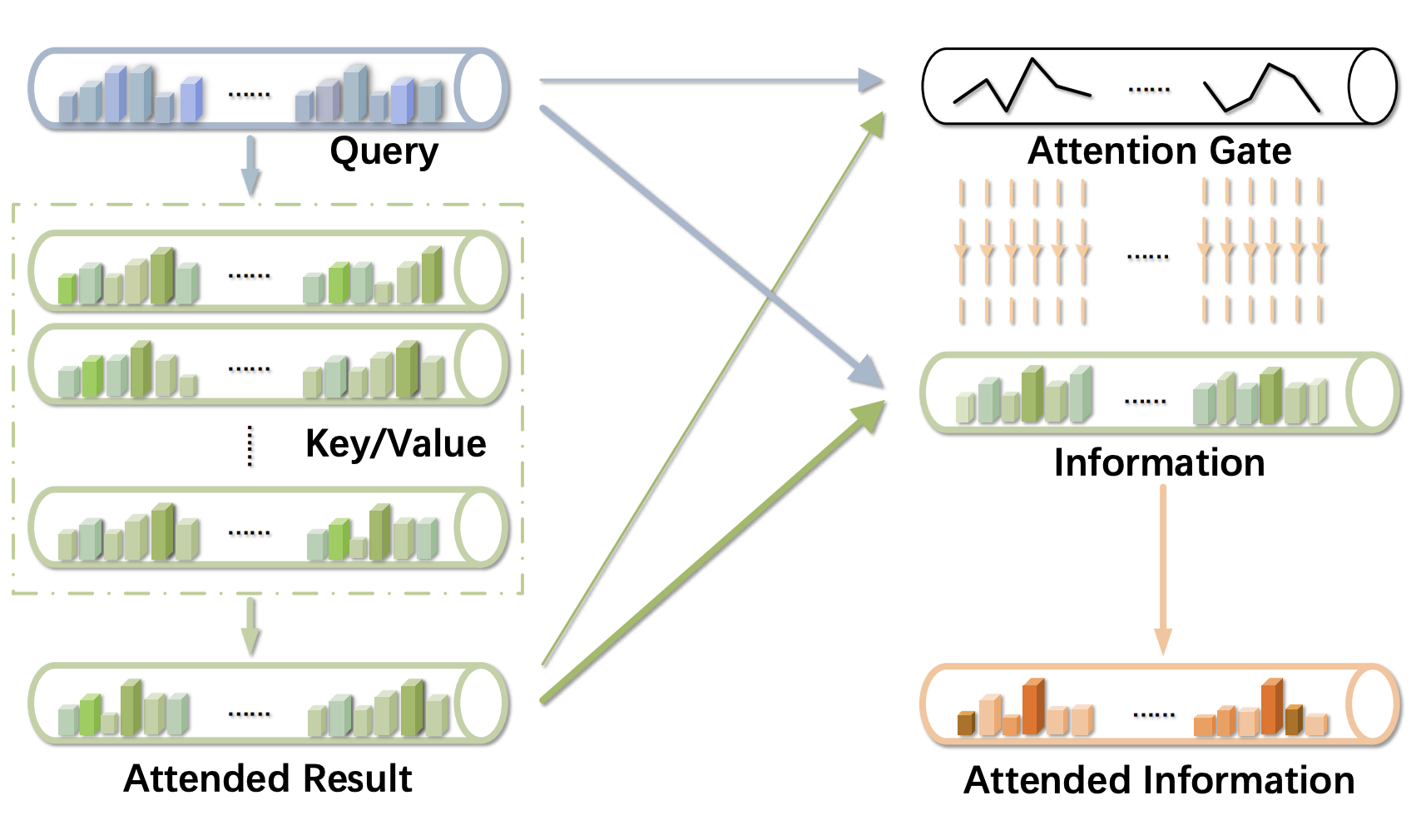
Attention on Attention for Image Captioning, IEEE/CVF International Conference on Computer Vision (ICCV), 2019
[PDF]
[CODE]
[BIBTEX]
[IMG]
@inproceedings{WXY_ICCV_2019,
author={Lun Huang and Wenmin Wang and Jie Chen and Xiao-Yong Wei},
booktitle={IEEE/CVF International Conference on Computer Vision (ICCV)},
title={Attention on attention for image captioning},
year={2022}}
- We extend the conventional attention mechanisms for a better modeling of the relevance between the query and attended results
- The proposed method is straightforward and can be "plug-in" to most of the previoius attention mechanisms
- We achieve a new state-of-the-art performance on image captioning
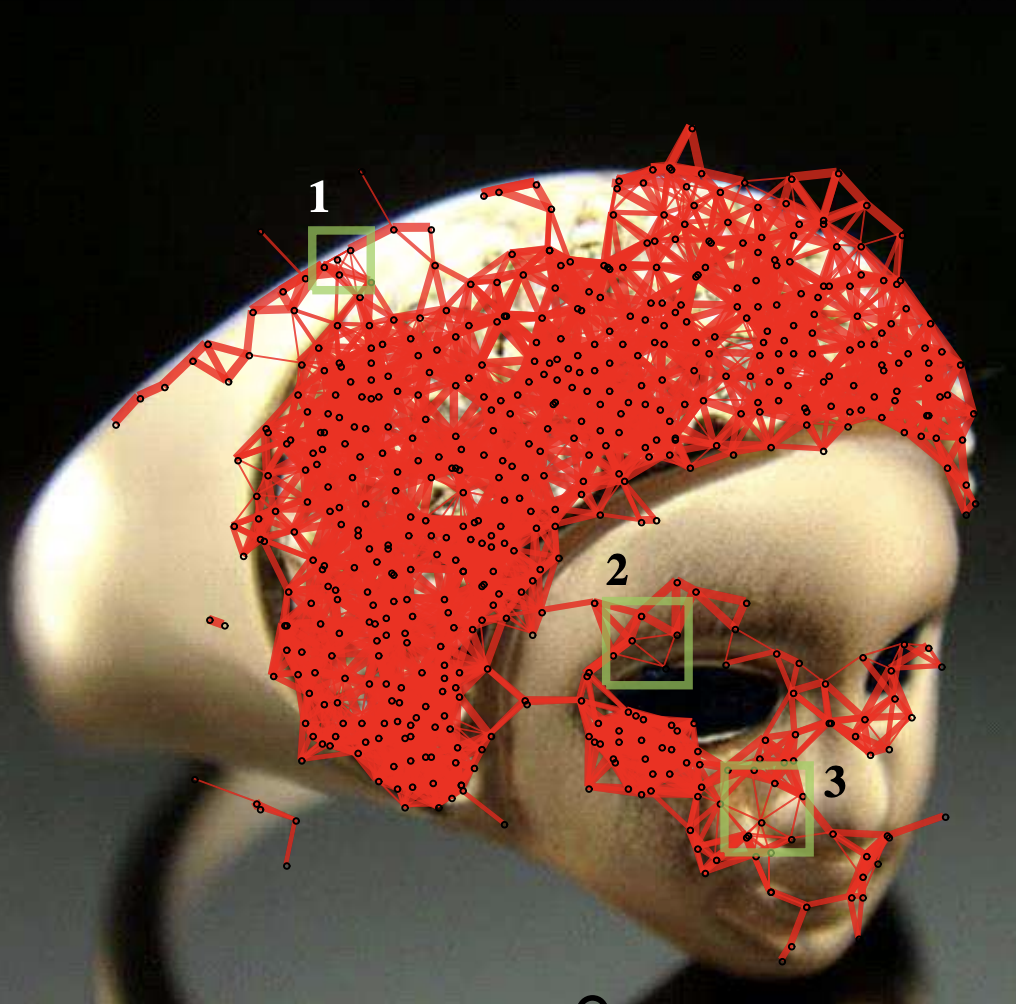
Contextual Noise Reduction for Domain Adaptive Near-Duplicate Retrieval on Merchandize Images, IEEE Transactions on Image Processing, 26 (8), 3896-3910, 2017
[PDF]
[BIBTEX]
[IMG]
@ARTICLE{WXY_NDR_TIP_2017,
author={Xiao-Yong Wei, Zhen-Qun Yang},
journal={IEEE Transactions on Image Processing},
title={Contextual Noise Reduction for Domain Adaptive Near-Duplicate Retrieval on Merchandize Images},
year={2017},
volume={26},
number={8},
pages={3896--3910}
}
- We propose a context graph to unify local features
- We implement the Anisotropic Diffusion on the context graph for domain adaptive nosie reduction
- We prove that contextual noise can be reduced using the sophisticated image filters
Coaching the Exploration and Exploitation in Active Learning for Interactive Video Retrieval, IEEE Transactions on Image Processing, 22 (3), 955-968, 2013
[PDF]
[BIBTEX]
[IMG]
@ARTICLE{WXY_CAL_TIP_2013,
author={Xiao-Yong Wei, Zhen-Qun Yang},
journal={IEEE Transactions on Image Processing},
title={Coaching the exploration and exploitation in active learning for interactive video retrieval},
year={2013},
volume={22},
number={3},
pages={955--968}
}
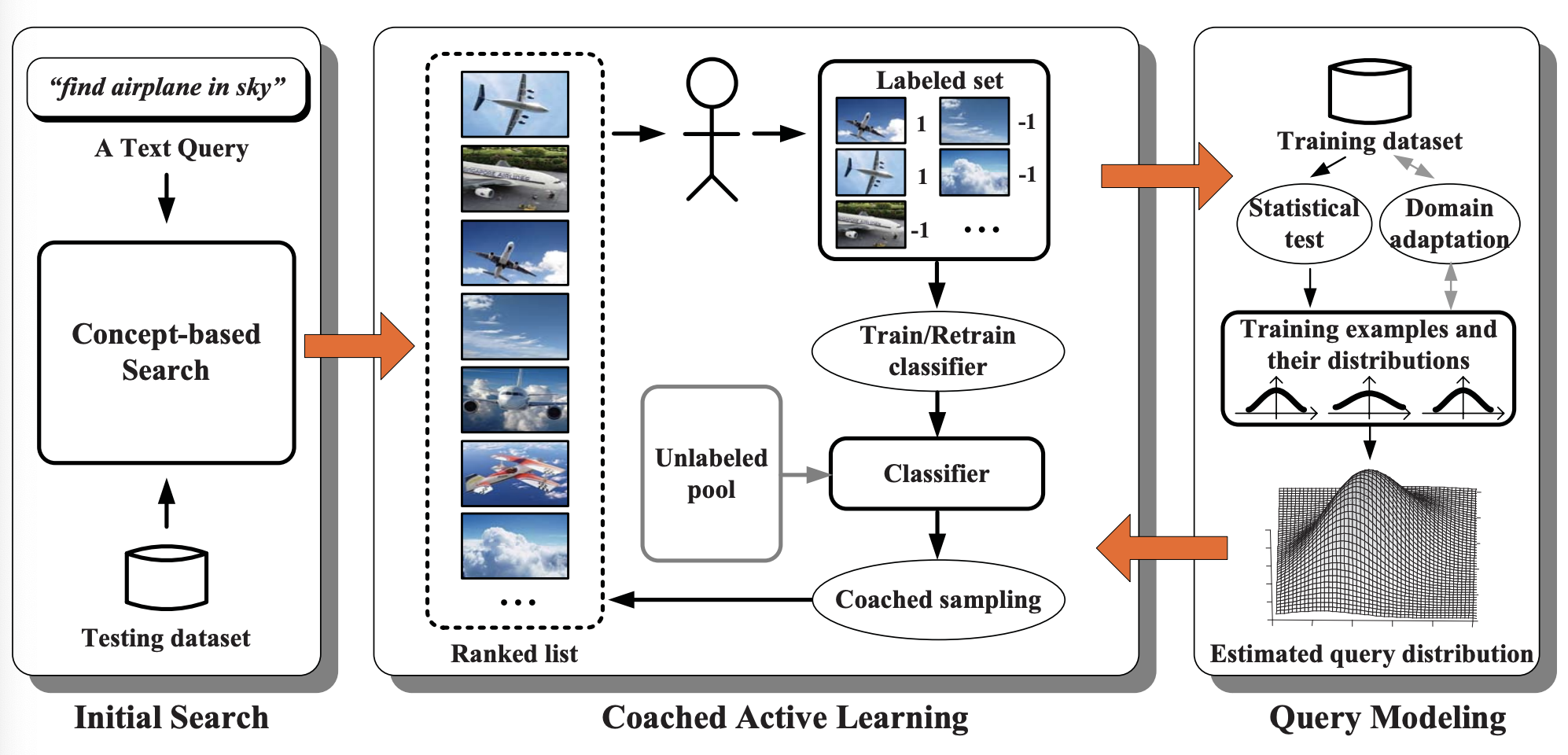
- We address the exploitation-exploration dellimma of using active learning for interactive search
- We make the query distribution predictable to avoid to searching in a completely unkown feature space
- We use the estimated query distribution as a coach to balance the immediate reward and long-term goal
Mining In-class Social Networks for Large-scale Pedagogical Analysis, ACM International Conference on Multimedia, 2012
[PDF]
[BIBTEX]
[IMG]
@inproceedings{WXY_InClass_2012,
author={Xiao-Yong Wei and Zhen-Qun Yang},
booktitle={ACM International Conference on Multimedia},
title={Mining In-class Social Networks for Large-scale Pedagogical Analysis},
year={2012}}
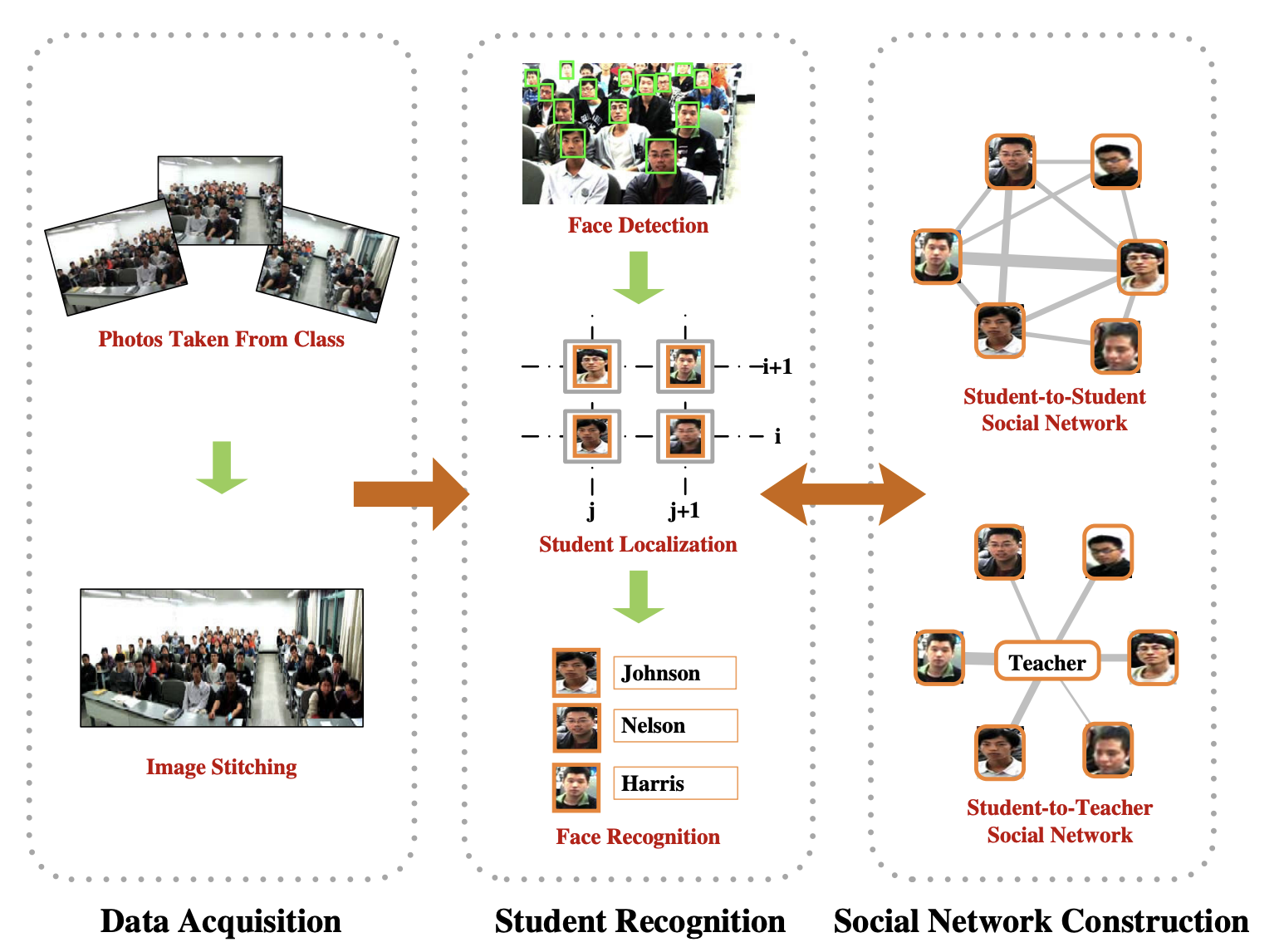
- This is one of the first work that uses facial recognition for pedagogical analysis
- It is widely reported by over 50 media
- In-class social networks are extracted automatically
- We answer the question whether sitting at front rows leads to better performance
Concept-driven Multi-modality Fusion for Video Search, IEEE Transactions on Circuits and Systems for Video Technology, 21 (1), 62-73, 2011
[PDF]
[BIBTEX]
[IMG]
@ARTICLE{WXY_concept_2011,
author={Xiao-Yong Wei, Yu-Gang Jiang, Chong-Wah Ngo},
journal={IEEE Transactions on Circuits and Systems for Video Technology},
title={Concept-driven Multi-modality Fusion for Video Search},
year={2011},
volume={21},
number={1},
pages={62-73}
}
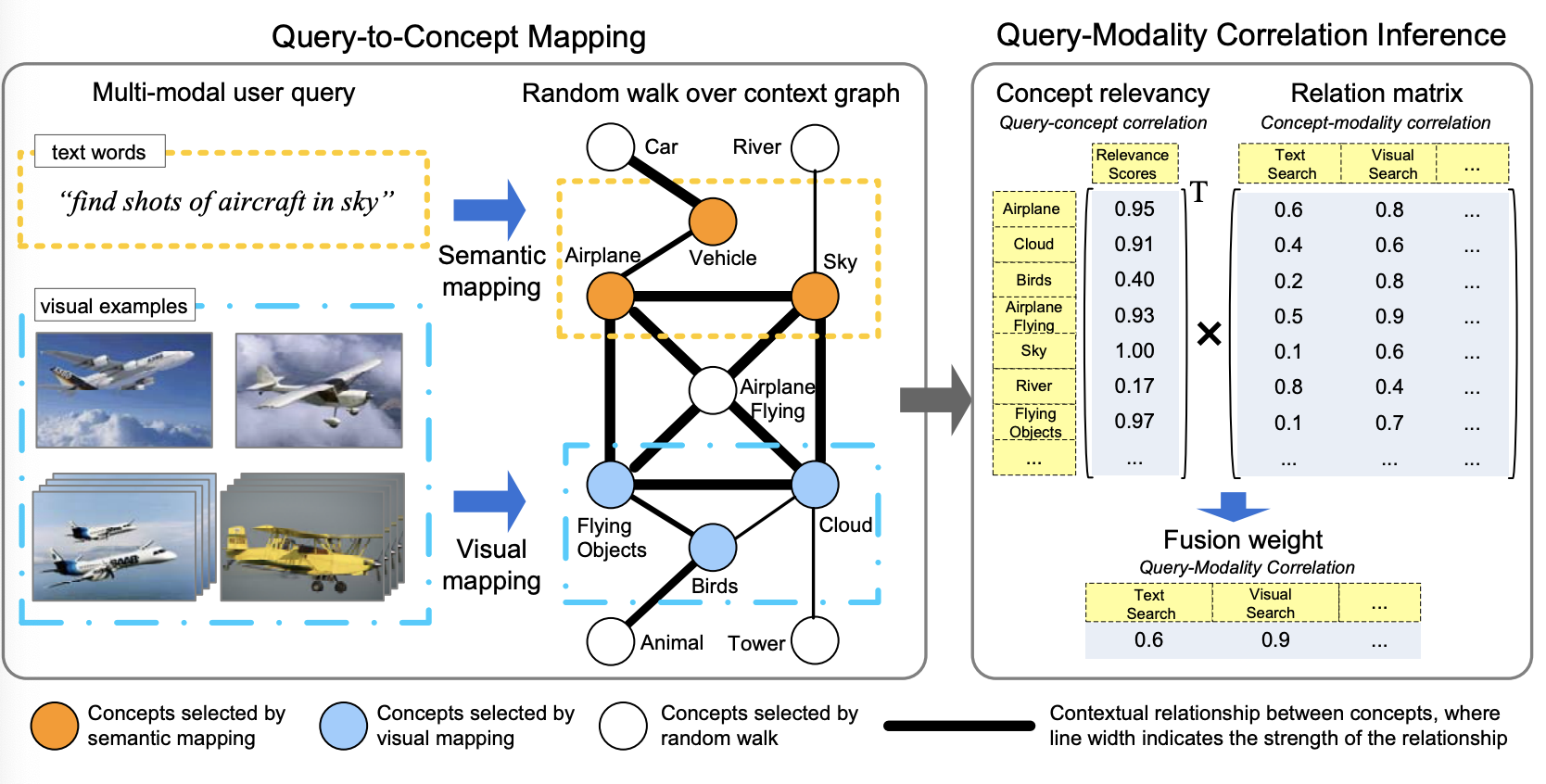
- We bridge the query-modality gap using a concept space
- We fusion the evidence collected from multiple sources using fuzzy composition
- We achieves near-optimal performance (from oracle fusion) for many test queries
Ontology-enriched Semantic Space for Video Search, ACM International Conference on Multimedia, 2007
[PDF]
[BIBTEX]
[IMG]
@inproceedings{WXY_MM_07,
author={Xiao-Yong Wei and Chong-Wah Ngo},
booktitle={ACM International Conference on Multimedia},
title={Ontology-enriched semantic space for video search},
year={2007}}
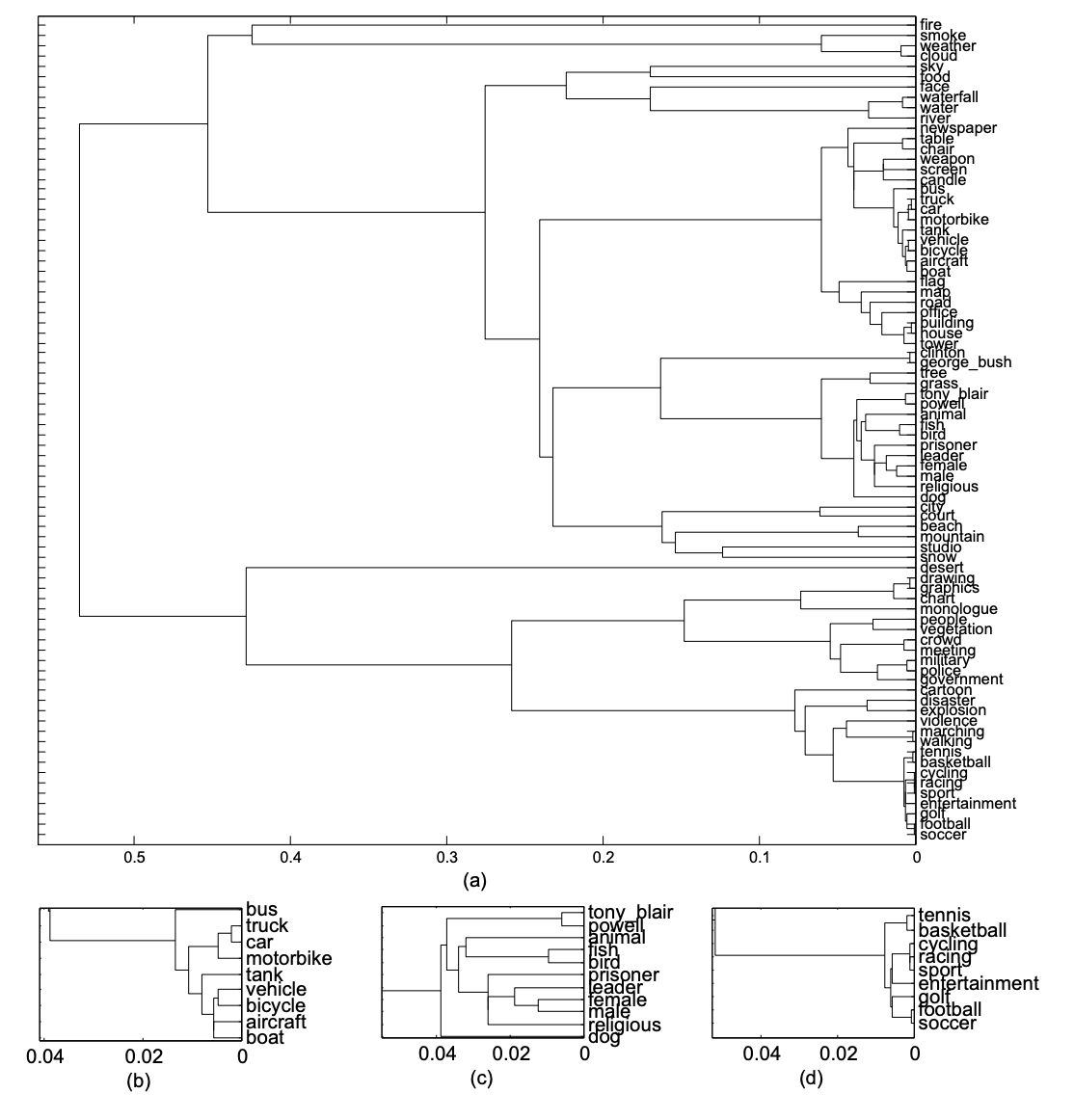
- We construct a sementic space to measure the qeury-concept similarity for video search
- The semantic space is enriched using WordNet in which we embed concepts as vectors
- The vectors makes the semantic relation computable
- This is one of the early embedding work prior to the Word2Vec
Contact
PQ829, Dept. of Computing, The Polytechnic University of Hong Kong